Ghost Hunter: The $28,000 Question Your Dashboard Won't Answer
Every cloud bill tells you what went up. None of them tell you why. Ghost-hunter is an AI investigator that reasons through your bill the way a senior SRE does: one hypothesis at a time, read-only, every command validated before it runs.
Avinash S
|
April 19, 2026
8 min read
It's 11:47 PM. The CEO sends a two-word email.
Subject: Bill?
The AWS bill went from $135,000 to $163,000 in a single month. The board call is at 9 AM tomorrow. The CFO wants a cause, not a number.
The on-call engineer opens the console. Sees the spike. Does not see the cause. Starts digging.
Three hours, eleven browser tabs, and one cold coffee later, the answer surfaces. A single forgotten GPU instance in us-east-1, launched two weeks ago by someone who has since left the team. $1.62 an hour. 24 hours a day. 18 days.
This scene plays out in every cloud-native company, every month. The senior SRE it takes to resolve it is one of the most expensive people in engineering.
I built Ghost-hunter to play that SRE. At 11:47 PM. When nobody else is awake.
Dashboards describe. They do not diagnose.
Cloud dashboards are the smoke detector. They tell you there is a fire. They cannot tell you which wire frayed.
The "why" lives in three places the dashboard cannot reach:
Command-line output from service-specific tools (aws, gcloud, kubectl)
Log data the dashboard never ingested
Tribal knowledge. Who launched what. Which account is test. What's normal for this team.
A human SRE walks that terrain by hand. They form a theory. Run a read-only command. Read the output. Adjust.
Ghost-hunter does the same. No human required at 11:47 PM.
Two detectives, not one
Most AI tools wrap a single model. You ask a question. It writes commands. It runs them. It tells you what it thinks.
For a chatbot, that's fine. For anything that touches your cloud, it's reckless.
Picture a detective investigating a scene. If the same person forms theories AND handles raw evidence, two things go wrong. They miss what a fresh eye would catch. And they're one bad assumption away from contaminating the scene.
Ghost-hunter uses two.
The lead detective. Forms theories. Weighs evidence. Decides what to investigate next. Never touches the crime scene directly. (This is Claude Opus.)
The evidence technician. Follows instructions. Collects samples. Writes one-line summaries. Signs off on the chain of custody before anything crosses. (This is Claude Sonnet.)
"Contaminating the scene" in this analogy is running a command that damages your cloud. The detective never writes commands. The technician writes them. A seven-gate safety system verifies them. Nothing runs until every gate signs off.
A case, five scenes
I ran Ghost-hunter against the FinOps Foundation's public FOCUS 1.0 sample. Real shape, anonymized data, no customer exposure. The dollar amounts are scaled down. The mechanics are what you'd see in production.
Scene 1. The scene of the spike
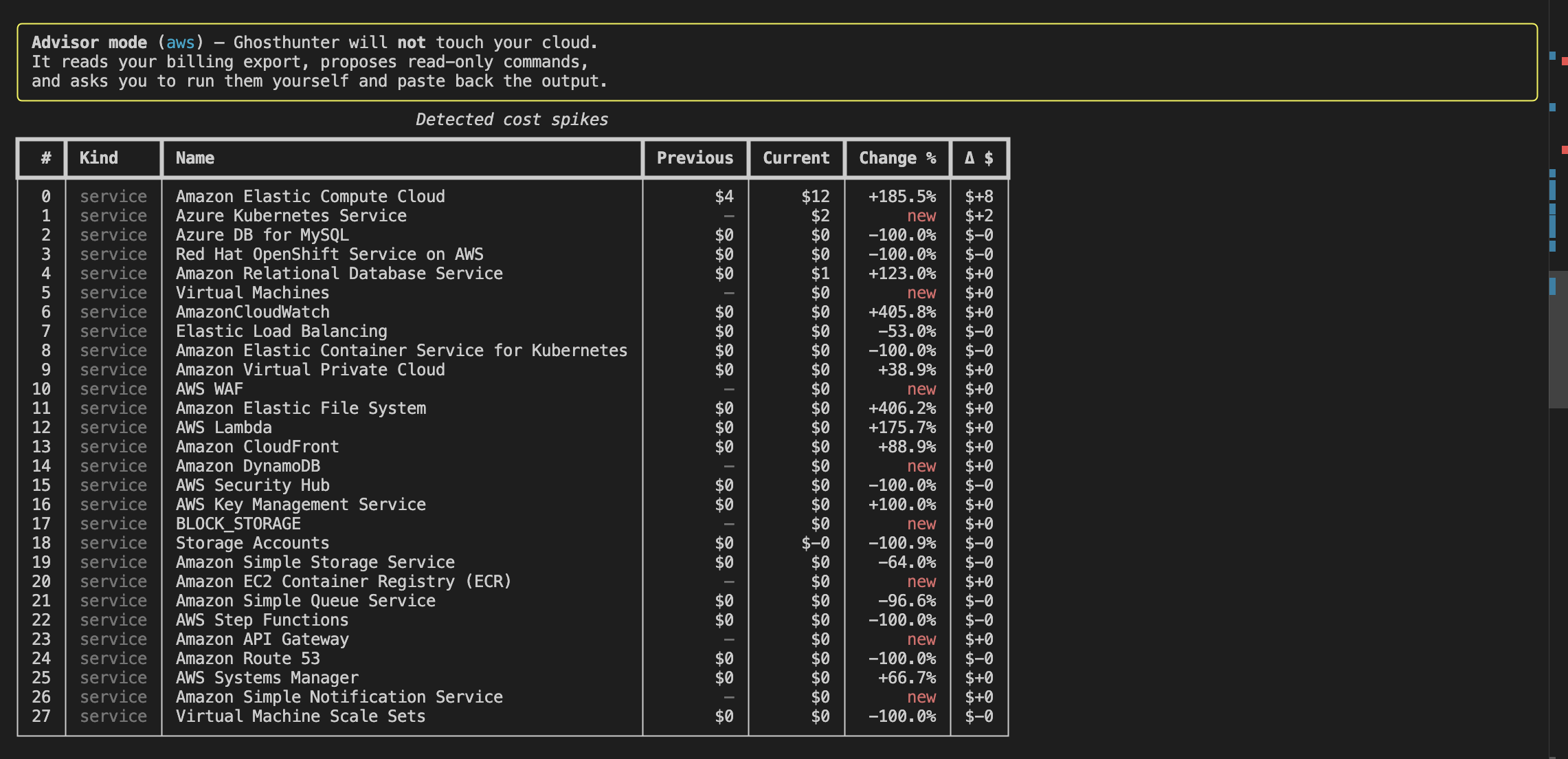
Ghost-hunter in advisor mode. "Will not touch your cloud. Reads your billing export, proposes read-only commands, asks you to run them yourself."
EC2 at the top of the list, up 185.5%. 27 other services scanned and ranked by dollar impact.
The investigation starts with a fact, not a guess.
Scene 2. The suspects
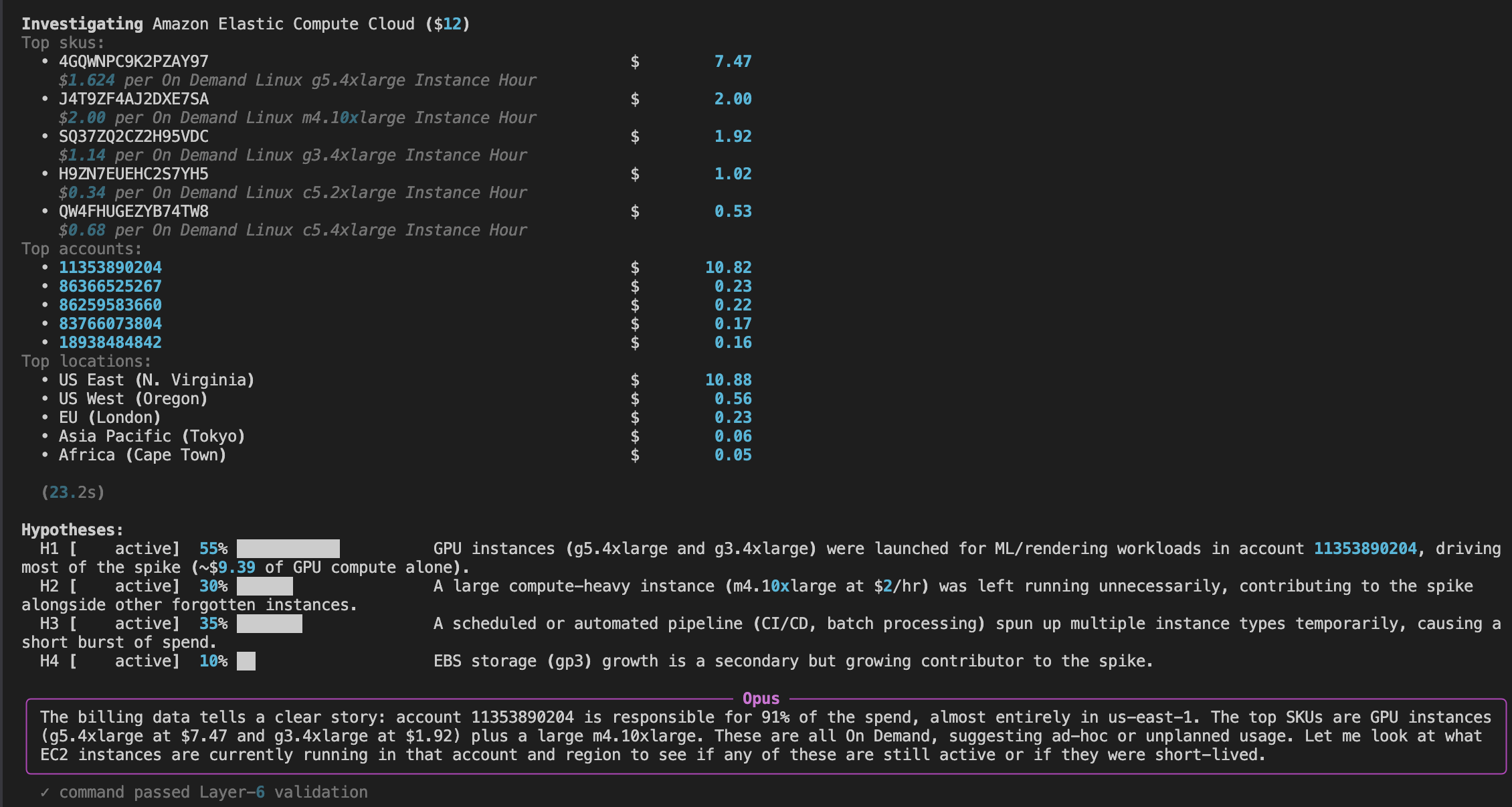
The lead detective pulls the file apart. Top SKUs. Top accounts. Top regions. One account, 11353890204, is responsible for 91% of the spend. 92% of it landed in us-east-1.
Four theories go on the board:
H1 (55%). GPU instances running for ML or rendering, driving most of the bill.
H2 (30%). A general-purpose instance left running longer than it should have.
H3 (35%). A CI or batch pipeline spinning up short-burst instances.
H4 (10%). Storage growth as a secondary contributor.
Each one has a confidence score. Each one is testable. The detective picks the strongest.
The evidence technician drafts a command. Read-only. Validated by four security layers. Copied to the user's clipboard automatically.
The user replies:
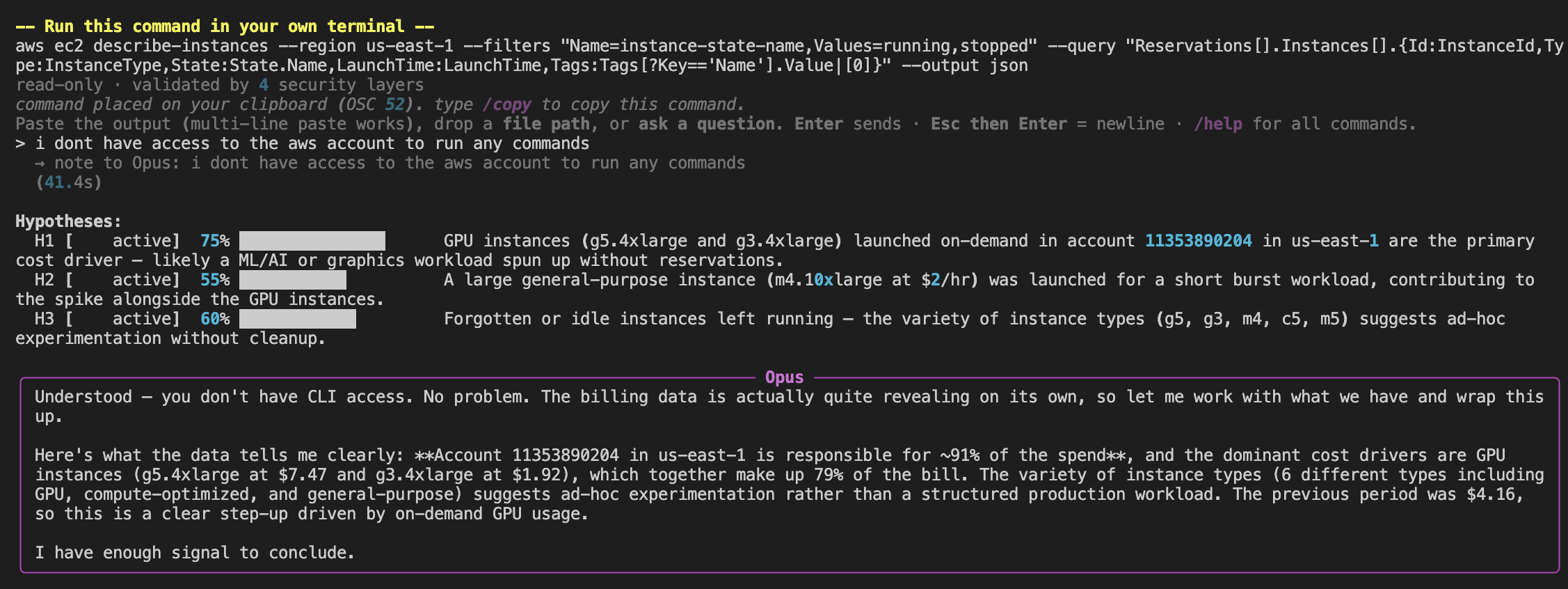
"i dont have access to the aws account to run any commands"
Most AI tools break here. Either they freeze. Or they hallucinate a result. Or they quietly pretend the user did run the command.
Ghost-hunter does none of that. The detective takes the refusal as information. Re-reads what's on the board. Updates the confidence scores (H1 climbs from 55 to 75). Concludes with what's actually provable from billing alone.
"Understood. You don't have CLI access. No problem. The billing data is quite revealing on its own. Let me work with what we have and wrap this up."
A fake confidence drop would be worse than no tool at all. Ghost-hunter lands on 72%. Not 95. Not 100. Seventy-two.
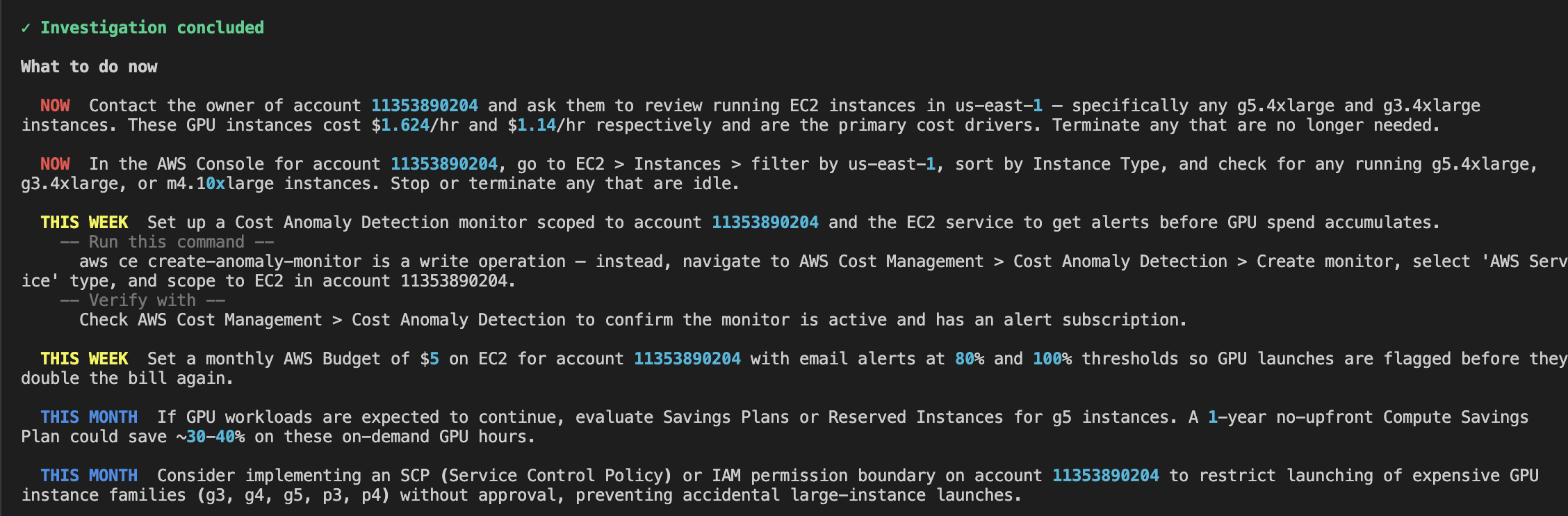
Scene 4. The plan
Not "do these twelve things and good luck." A prioritized ladder.
NOW. Contact the owner of account 11353890204. Check running g5.4xlarge instances in us-east-1.
THIS WEEK. Set a Cost Anomaly Detection monitor. Add a $5 budget with email alerts at 80% and 100%.
THIS MONTH. Evaluate Savings Plans. Add an IAM guardrail to block expensive GPU launches without approval.
Every "NOW" item is under five minutes. Nothing in the list is a write command against production. Ghost-hunter will never tell you to delete, terminate, or modify anything without your finger on the key.
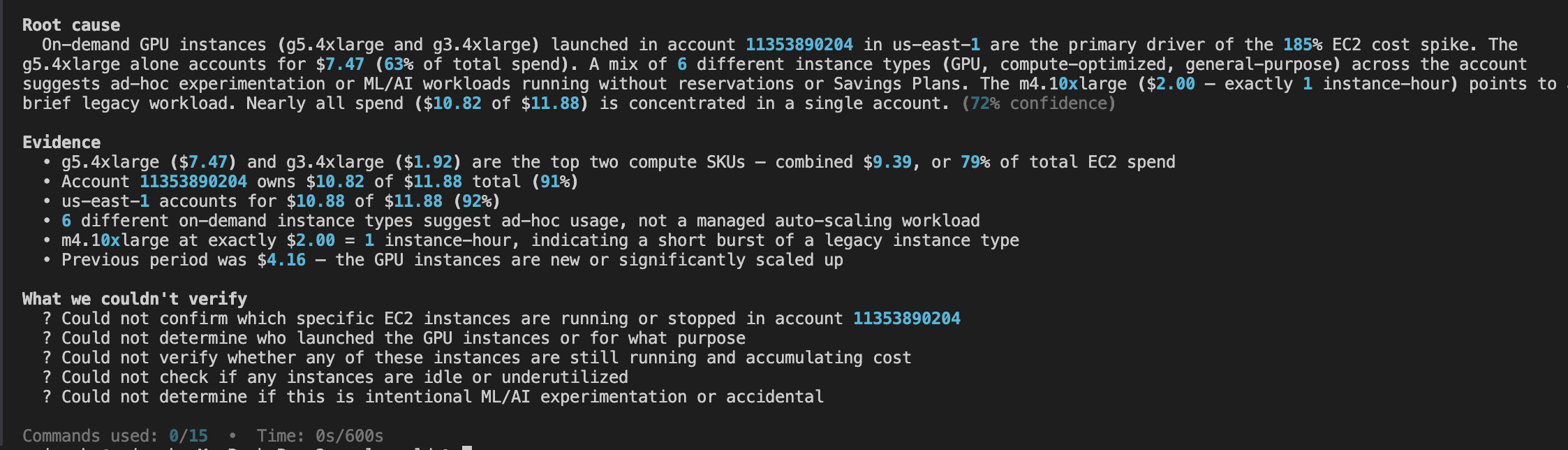
Scene 5. The verdict, with honest gaps
A root cause. Five cited pieces of evidence. A list of five things Ghost-hunter could not verify.
This part matters more than the conclusion itself.
Most AI tools close with false certainty because false certainty feels polished. Ghost-hunter tells you what it does not know. "Could not confirm which specific EC2 instances are running.""Could not determine who launched the GPU instances or for what purpose."
That transparency is what makes the conclusion trustworthy. You can read the transcript, see what was cited, see what was not, and decide if 72% is good enough to act on.
The seven doors
Every command Ghost-hunter proposes passes through a vault with seven doors. Miss any one door, the command dies.
1. Fast reject shell metacharacters blocked (;, &&, unquoted $())
2. Allowlist is this verb on the read-only list?
3. Flag check every flag safe for this verb?
4. Input hygiene length, encoding, empty-command?
5. Budget caps on commands, cost, time per run
6. Semantic check does this actually test the stated hypothesis?
7. Sandbox environment isolation (active mode only)
A system that sometimes lets through commands its validator was unsure about is a system that will one day run delete by accident. Ghost-hunter has no "helpful override." A command that cannot pass every door does not run.
Three lines I refuse to cross
No writes. Ever. Read-only is the whole product. The detective does not hold the keys to the cloud.
No hardcoded answers. Most "AI FinOps" tools win benchmarks by memorizing patterns. "If NAT Gateway plus high bytes, the answer is missing VPC endpoint." Ghost-hunter refuses. The CI pipeline literally fails commits that put scenario names in prompts. If the reasoning isn't in the transcript, it isn't in the product.
No data leaves your machine. Your bill stays local. The only thing that moves is compressed evidence summaries, through your own Anthropic API key.
Why this matters
Most AI tools in this space are lookup tables with a nice voice. They recognize the shapes they were trained on. They miss the shapes they weren't.
Ghost-hunter is slower. On a known pattern, a memorizing tool will beat it every time.
Ghost-hunter wins on the bill nobody has seen before. Your bill. Your configuration. The spike caused by your ML team's experiment, your third-party vendor's bug, the intern who cloned a production pipeline for testing. Every hypothesis, every command, every piece of evidence sits in a transcript you can read.
You do not trust the conclusion because an AI said so. You trust it because you can audit the reasoning yourself.
That's the product.
Private beta
Ghost-hunter is not yet public. If you run cloud infrastructure and you've ever been the person answering the 11:47 PM email, I'll open access to you first.
Book a 20-minute call and I'll walk you through Ghost-hunter against a billing export of your choosing. Or send me a note with what you'd want it to solve first.
Avinash S is the founder of MatrixGard. Cloud and DevSecOps for startups who cannot afford the team they need. Almost a decade of building, breaking, and securing cloud infrastructure.
MatrixGard
Ready to see Ghost-hunter on your bill?
Ghost-hunter is in private beta. Book a call and I'll walk you through an investigation on a billing export of your choosing.